OU-EXT Scalability tests
The Test Environment
The ExtAFInitReferenceTable Archive Function is applied on dh-node10. The connection to the database is made via the connection manager using its public ip. The database is db.prod1.euclid.target.rug.nl/euclid and the Gaia DR2.0 input catalogue is accessed via a database link.
dh-node10 connects to the database from a 129.125.x.x/24 ip. According to iperf, using the same subnet provides typical speeds of 8.75 Gbit/s from dh-node10 to the connection manager vm and vice versa.
The Test
In the Archive Function the data is selected, transformed, inserted, and committed in sections of the sky. There are 16384 sections that contain 1 million sources on average. For each section three steps can be identified in the Archive Function
- SELECT - Query database for a section of Gaia DR2.0 and transfer the result to the machine running the Archive Function.
- TRANSFORM - On the machine running the Archive Function, generate the columns for the ReferenceTable, which includes the calculation of the EuclidID and HEALPix value.
- INSERT - Transfer data from the machine running the Archive Function to the database and insert into the ReferenceTable and commit.
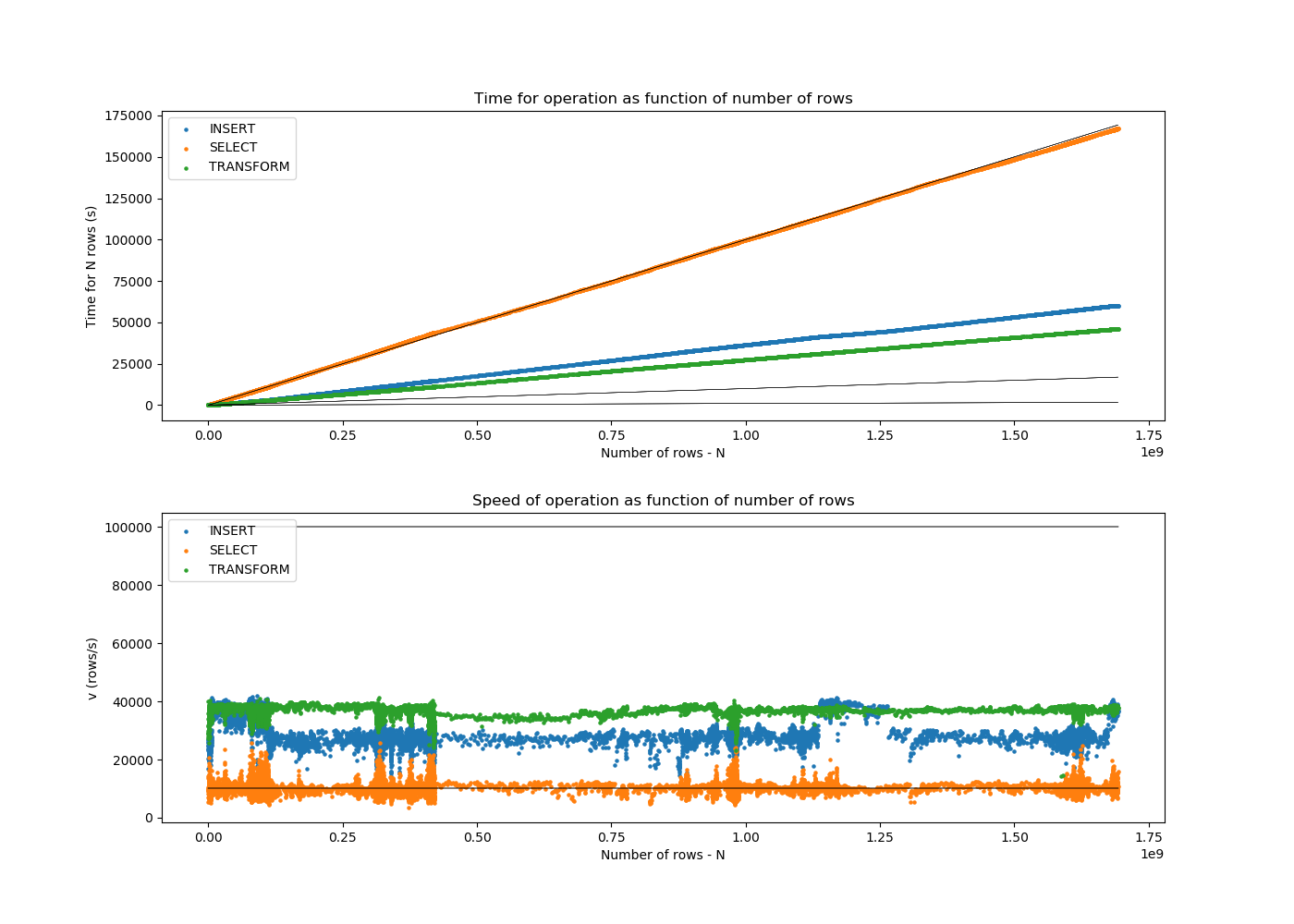
The start and end times, as well as the number of sources are registered for each of the individual SELECT, TRANSFORM, and INSERT steps of each section. From these one can both derive a plot showing the number of sources per second as function of time and the scalability plot showing the total time as function of the cumulative number of sources.
The Result
The following figure includes lines that represent speeds of 1, 10, or 100 MByte/s that are typical of network hardware. An average value of 100 bytes per source is assumed. This is a rough estimate.
The bottom figure roughly corresponds to the first derivative of the top figure.
Conclusions
- SELECT took 46.6 hours.
- TRANSFORM took 12.9 hours.
- INSERT took 16.8 hours.
Notes
The TRANSFORM is expected to be cpu bound. This appears to be the case when comparing dh-node10 which has a E5-2680 v4 @ 2.40GHz and a Kapteyn desktop containing a i7-4770S CPU @ 3.10GHz. The processes were estimated to take 11.7 hours and 9 hours, respectively, which means that dh-node10 is 11.7h / 9h = 1.30 times slower than the Kapteyn desktop. That is equivalent to a single core processor speed ratio of 3.10GHz / 2.40GHz = 1.29.
The SELECT should be I/O bound or network bound, yet fetching the data to a datahandling node is only ~6% faster than to get it a machine inside the Kapteyn intranet.
Fetching 7 columns from 1,692,919,135 rows translates into 1692919135 * 100 bytes / 46.6 h / 3600 s/h = ~1009 kbyte/s. The 100 bytes are assuming 8 bytes per column of IEEE type BINARY_DOUBLE and allowing for quite some overhead in the transfer protocol. In other words, the SELECT speed is roughly about 1 Mbyte/s = 10 Mbit/s. This is not even close to network speeds of 1 Gbit/s, let alone 10 Gbit/s. The limit is possibly imposed by the fact that the SELECT query is performed per SOURCEID range as there is no index on that column.
The INSERT is almost three times as fast as the SELECT, at a speed of about 2.8 Mbyte/s.